대규모 언어모델(LLM)을 기반으로 한 생성AI는 챗봇, 스토리텔링, 검색, 고객지원 등 다양한 산업에 걸쳐 활용되며 폭발적으로 성장하고 있다. 이에 따라 하루 수십억 개 이상의 토큰을 처리하는 서비스가 등장하고 있으며, 연산 비용과 추론 지연(latency)이 기업 운영의 핵심 과제로 떠오르고 있다. 특히 사용자 경험을 좌우하는 실시간 응답성과, 클라우드 컴퓨팅 자원 사용 효율성은 모델 경량화 및 최적화를 통해 해결해야 할 시급한 문제로 부상했다.
AI 기반 소셜 플랫폼 기업 차이(CHAI)가 자사 소셜 AI 플랫폼을 4비트 모델 양자화에 성공해 플랫폼 응답 속도를 56% 개선했다고 밝혔다.
이번 기술은 하루 1.2조 토큰을 처리하는 차이의 초대형 AI 운영 환경을 고려한 최적화 방식으로, GPT-J 기반 모델을 기준으로 성능 저하 없이 모델 크기와 연산 비용을 동시에 줄였다는 점에서 주목된다.
4비트 모델 양자화로 추론 지연 최소화
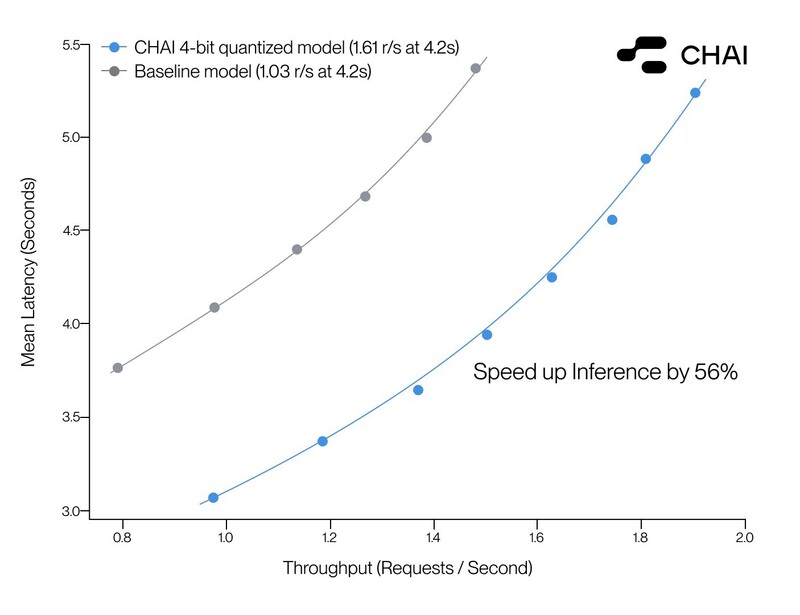
차이는 INT8, FP16, 하이브리드 방식 등 다양한 양자화 기법을 실험한 끝에 최적의 4비트 구성으로 LLM 추론 효율을 극대화했다. 그 결과, 다음과 같은 주요 성과를 얻었다.
첫째, 사용자 응답 시간 기준으로 56% 이상 빠른 추론 속도를 달성했다. 둘째, 모델의 메모리 사용량이 감소하면서 전반적인 컴퓨팅 비용을 절감했다. 셋째, 정량화 후 모델 성능 저하는 1% 미만으로, 실사용 기준에서 정확도 손실 없이 모델 경량화에 성공했다. 이 같은 성과가 2천만 달러 규모의 컴퓨팅 인프라 투자와 알고리듬 최적화 전략이 결합된 결과다.
차이는 단순한 챗봇이 아닌 사용자가 직접 AI 캐릭터를 만들고 대화할 수 있는 소셜 생성AI 플랫폼이다. Z세대를 중심으로 인기를 얻고 있으며, 고도화된 엔터테인먼트형 AI를 통해 독자적 입지를 다지고 있다. GPT-J 오픈소스 모델을 기반으로 한 차이는 챗GPT나 라마(LLaMA)보다 먼저 백만 사용자 돌파 기록을 세운 바 있다.