인텔은 20일 신규 인텔 oneAPI 2023 툴을 공개했다. 해당 툴을 인텔 디벨로퍼 클라우드(Intel Developer Cloud)와 공식 리테일 채널을 통해 제공한다. 신규 oneAPI 2023 툴은 4세대 인텔 제온 스케일러블 프로세서는 물론 인텔 제온 CPU 맥스 시리즈, 플렉스 시리즈와 신규 맥스 시리즈를 포함한 인텔 데이터 센터 GPU를 지원한다.
인텔 oneAPI 2023은 향상된 성능과 생산성을 제공하며, 개발자들이 비(非)인텔 GPU 아키텍처를 위한 SYCL 코드를 쉽게 작성할 수 있도록 신규 코드플레이(Codeplay) 1 플러그인을 지원한다. 인텔은 신규 표준 기반 툴을 통해 사용자가 하드웨어를 선택할 수 있도록 선택지를 제공하며, 멀티 아키텍처 시스템에서 실행되는 고성능 애플리케이션을 쉽게 개발할 수 있도록 지원한다.

새롭게 공개하는 인텔 2023 개발자 툴에는 oneAPI로 구동되는 CPU, GPU, FPGA를 위한 고성능 멀티 아키텍처 애플리케이션을 구축하기 위한 최신 컴파일러, 라이브러리, 분석과 포팅 도구, 최적화된 인공지능과 머신러닝 프레임워크가 포함돼 있다. 개발자는 툴을 사용해 목표하는 성능을 빠르게 달성하고, 단일 코드베이스를 사용해 시간을 절약, 혁신에 더 많은 시간을 쏟을 수 있다.
신규 oneAPI 툴은 개발자가 인텔 어드밴스드 매트릭스 익스텐션(Intel AMX), 인텔 퀵 어시스턴트 테크놀로지(Intel QAT), 인텔 AVX-512, bfloat16 등을 지원하는 4세대 인텔 제온 스케일러블 프로세서와 인텔 CPU 맥스 시리즈 프로세서 하드웨어 기반 AV1 인코더를 사용하는 플렉스 시리즈를 포함한 인텔 데이터 센터 GPU, 데이터 유형 유연성을 갖춘 맥스 시리즈 GPU, 인텔 Xe 매트릭스 익스텐션(Intel XMX), 벡터 엔진, 인텔 Xe Link 등의 인텔 하드웨어의 고급 기능을 활용할 수 있도록 지원한다.
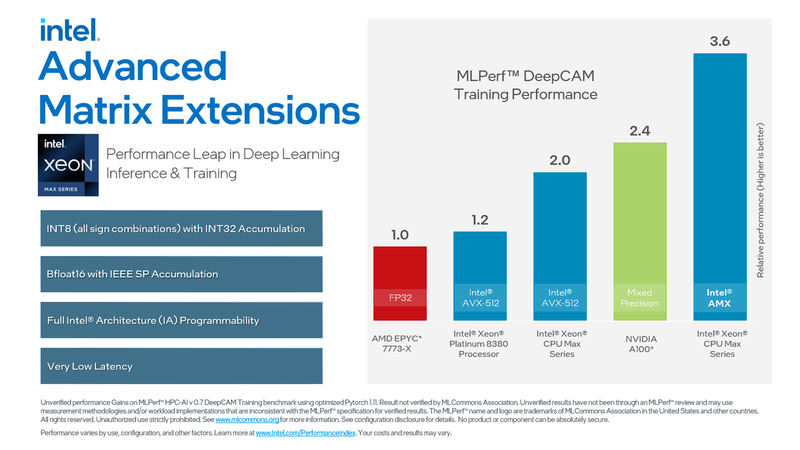
MLPerf DeepCAM 딥러닝 추론 및 학습 성능 벤치마크에서 AMD 제품을 기준으로 엔비디아는 2.4배 높은 성능을, 인텔 oneAPI 딥 뉴럴 네트워크 라이브러리(oneDNN)2 기반 인텔 AMX를 사용한 인텔 제온 CPU 맥스는 3.6배 높은 성능을 달성했다.
6개 맥스 시리즈 GPU에 오프로드되고 하나의 oneAPI 도구로 최적화된 인텔 제온 맥스 CPU 상에서 실행되는 대규모 원자와 분자 병렬 시뮬레티어(LAMMPS) 워크로드 성능의 경우, 3세대 인텔 제온 혹은 AMD 밀란 대비 최대 16배 높은 성능을 기록했다.
인텔 포트란 컴파일러(Intel Fortran Compiler)는 포트란 2018 등 포트란 언어 표준을 지원하며, OpenMP GPU 지원을 확대해 표준 준수 애플리케이션 개발 속도를 제공한다. 또한 확장된 OpenMP 오프로드 기능을 갖춘 인텔 oneAPI 매스 커널 라이브러리(oneMKL)로 포터빌리티를 향상시켰으며, 인텔 oneAPI 딥 뉴럴 네트워크 라이브러리(oneDNN)는 인텔 AMX, 인텔 AVX-512, VNNI 및 bfloat16을 포함한 4세대 인텔 제온와 인텔 맥스 CPU 프로세서의 고급 딥 러닝 기능을 지원한다.
이외에도 풍부한 SYCL 지원과 강력한 코드 마이그레이션과 분석 도구는 개발자들이 멀티 아키텍처 시스템을 위한 코드를 더 쉽게 개발할 수 있도록 지원해 생산성을 향상한다.
인텔 oneAPI DPC++/C++ 컴파일러는 엔비디아와 AMD GPU용 코드플레이(Codeplay) 소프트웨어의 신규 플러그인을 지원, SYCL 코드 작성을 간소화하고 이러한 프로세서 아키텍처 전반에서 코드 이식성을 확대한다. 이를 통해 플랫폼 간 생산성 향상을 위한 통합 툴이 포함된 통합 구축 환경을 제공한다. 인텔과 코드플레이는 엔비디아 GPU용 oneAPI 플러그인을 시작으로 제품을 우선 지원할 방침이다.
오픈소스 SYCLomatic을 기반으로 하는 인텔 DPC++ 호환성 도구에 100개 이상의 CUDA API가 추가돼 더욱 간편하게 CUDA에서 SYCL 코드 마이그레이션이 가능하다.
또한 사용자는 인텔 VTune 프로파일러(Intel VTune Profiler)를 통해 MPI 불균형을 식별할 수 있으며, 인텔 어드바이저(Intel Advisor)는 인텔 데이터 센터 GPU 맥스 시리즈에 자동 루프라인 분석 기능을 추가, 메모리, 캐시 또는 컴퓨팅 병목 현상과 원인을 식별하고 우선순위를 지정한다. CPU에서 GPU로 오프로드 시 데이터 전송 재사용 비용을 최적화하기 위한 실용적인 통찰력을 제공한다.
48%의 개발자가 두 종류 이상의 프로세서를 사용하는 이기종 시스템을 목표로 하고 있기 때문에, 실제 워크로드의 범위와 규모가 증가하는 문제를 해결하기 위해서는 보다 효율적인 멀티 아키텍처 프로그래밍이 필요하다. 개발자는 인텔의 표준 기반 멀티 아키텍처 도구를 사용하고 개방되고 통합된 프로그래밍 모델인 oneAPI를 사용해 CPU와 가속기를 위한 하드웨어, 성능, 생산성, 코드 이식성을 자유롭게 선택할 수 있다.
관련기사
- '윈드리버 헬릭스' 인텔 프로세서 지원으로 항공·우주·국방 분야 경쟁력 강화
- 컴플라이언스 충족시키는 글로벌 의료 AI 협력 프로젝트
- '무어의 법칙' 지속 위한 인텔, "2030년까지 1조 개의 트랜지스터 집적할 것"
- 기다렸다! 4세대 인텔 제온 스케일러블 프로세서 기반 시스템
- 모바일 플랫폼 날개다는 24코어 13세대 인텔 코어 모바일 프로세서 라인업
- 인텔 제온 스케일러블 프로세서로 AI 컴퓨팅 효율성↑
- LGA 소켓 탑재한 에지 컴퓨팅용 'COM-HPC'…워크로드 통합 지원
- 엔비디아, AI·XR 전문가 위한 차세대 워크스테이션 플랫폼 공개
- 임베디드, 클라우드, 네트워킹 환경 위한 고성능 고효율 FPGA '인텔 애질렉스 7'
- ATUS, AMD와 손잡고 이벤트 기반 비전 센서 개발 나선다
- 인텔, 생성AI와 HPC 위한 개방형 데이터센터 솔루션과 기술 공개
- PCIe 5.0과 CXL 지원하는 R-타일 내장 '인텔 애질렉스 7 FPGA'
- AMD, 자율주행차 비용효율 높이는 FPGA 출시
- 인텔, 메테오 레이크 출시에 맞춰 주요 프로세서 브랜드 개편안 발표
- 인텔, AI 개발 가속하는 '산업별·기능별 레퍼런스 키트' 공개