
머신러닝(Machine Learning)의 한 분야였던 ‘딥러닝’으로 이름지어진 신경망(Neural Network) 기술은 2012년 이미지넷 대회 우승으로 큰 주목을 받았다. 그리고, 10여년이 지나는 동안, 바둑을 두는 인공지능 ‘알파고(Alpha Go)’, 그림을 그리는 인공지능 ‘스테이블 디퓨전(Stable Diffusion)’, 그리고 인간처럼 대화하는 챗GPT까지 다양한 분야에서 큰 성과를 내고 있다.
이같은 딥러닝의 성공은 기존의 통계적 머신러닝과는 다르게, 훈련에 사용되는 데이터의 특성을 자동으로 추출할 수 있는 딥러닝의 특징에서 기인한다. 예를 들어 다음 그림과 같이 사진에서 자동차를 판별하는 인공지능 시스템을 구축하는 경우를 생각해보자.
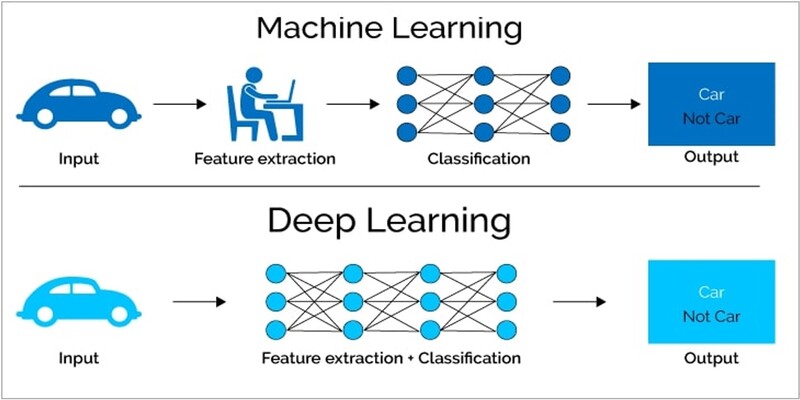
기존의 통계적 머신러닝 기술에서는 바퀴, 창문, 배기구 등 자동차가 갖는 특징(feature)을 사람이 지정하고, 이렇게 지정된 특징을 바탕으로 판별을 수행한다. 그런데, 자동차 사진은 다양한 상황에서 찍을 수 있다. 위에서 혹은 옆에서, 화창한 날에 혹은 흐린 날에 따라 자동차는 다양한 모양과 색깔을 보여준다. 따라서, 자동차의 공통된 특징을 기술하기에는 상당한 어려움이 있다.
반면에 딥러닝 기술에서는 자동차의 특징을 지정하지 않는다. 주어진 사진을 그대로 딥러닝 인공지능 시스템에 입력하여 판별을 진행한다. 딥러닝 모델은 스스로 자동차의 특징을 추출(feature extraction)한다. 사람이 특별히 지도하지 않아도 훈련에 사용된 데이터에서 자율적으로 판별에 사용될 적확한 특징을 찾아내는 것이다.
데이터의 특징을 찾는 ‘표현 학습’
정보를 처리하는 작업에서는 많은 경우, 데이터의 표현 방법에 따라서 작업이 매우 쉬워질 수도 혹은 어려워질 수도 있다. 예를 들어 다음과 같은 로마 숫자를 살펴보자.
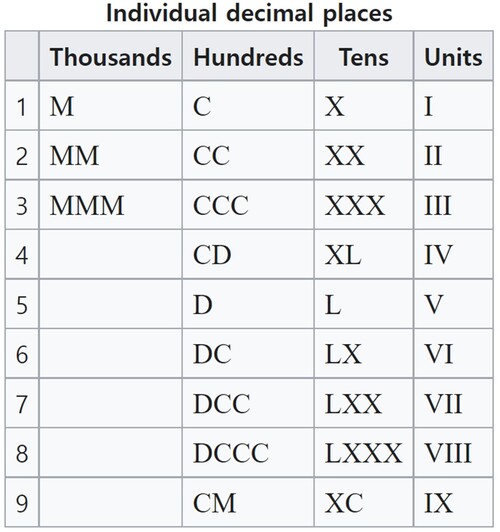
이 표를 참조해서 ‘DCCLXXXIX - CCXLVI’를 계산해보라.
쉬워 보이지 않는다. 이 문제를 우리가 현재 사용하는 숫자로 표현하면 ‘789 – 246’과 같다.
이처럼 정보를 처리할 때, 표현 방식에 따라 난이도가 크게 변할 수 있음을 알 수 있다.
전통적인 머신러닝에서는 주어진 작업을 효과적으로 수행할 수 있는 데이터의 표현을 찾기 위해 해당 분야 전문가의 지식을 활용했다.
대표적으로 초기 자동 번역(Machine Translation) 시스템에서는 언어학자가 각 언어의 특징을 연구하고, 그 특징을 기반으로 번역 규칙을 만들었다. 이렇게 만들어진 규칙을 기반으로 번역 프로그램을 작성했다. 그러나 언어는 단순한 규칙(문법)으로 설명하기에는 너무나 많은 예외 사항이 존재한다.
이를 해결하기 위한 방법으로 통계적인 접근이 시도되었다. 구글은 2000년 초 통계적 확률을 기반으로 구글 번역(Google Translation)을 만들었다. 머신이 자율적으로 찾은 통계 규칙 기반 시스템은 그동안 사용하던 전문가의 규칙 기반 시스템보다 더 효과적이었다. 이를 빗대 당시 컴퓨터 언어학의 선구자인 프레데릭 옐리넥(Frederick Jelinek)은 "언어학자를 해고할 때마다 음성 인식기의 성능이 올라간다”는 농담을 남기기도 했다.
인공지능의 언어 능력을 현재 챗GPT 성능까지 끌어 올린 것은 딥러닝의 표현(representation)을 학습하는 능력이다. 딥러닝 시스템은 대량의 자료(데이터)를 훈련해 언어의 의미를 적확하게 담은 숫자 표현을 만들어낸다. 표현의 적합성은 모델의 크기에 비례해, 상승했다. 챗GPT와 같은 대형 딥러닝 모델이 학습한 적확한 의미를 담은 숫자 표현은 번역 작업을 매우 쉽게 만들었다. 학습된 딥러닝 시스템은 번역할 언어를 컴퓨터의 언어인 숫자로 바꾸고(인코딩 과정), 다시 그 숫자를 목표로 하는 언어로 바꿈(디코딩 과정)으로써 번역을 완성한다.
언어학자의 도움도, 통계적 수치 분석의 도움도 없이 대형 딥러닝 모델이 스스로 학습한 표현 기반의 현재의 번역 시스템은 매우 자연스러운 번역물을 생성한다.
비정형 데이터의 표현 학습에 최적화된 딥러닝
딥러닝 시스템은 언어, 소리와 이미지 등 전통적인 머신러닝 시스템에서 다루기 어려웠던 데이터를 다루기 쉬운 형태의 표현으로 바꾸는 표현 학습(Representation Learning)능력을 보여준다.
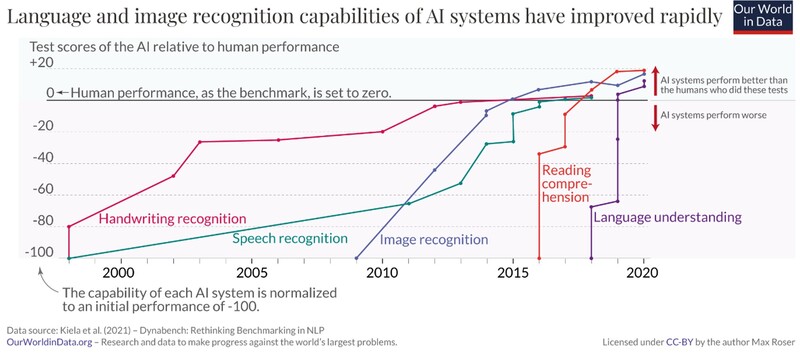
아래의 그림은 표현 학습 능력을 기반으로 발전한 딥러닝의 빠른 성능 향상을 나타낸다. 딥러닝 기술은 2014년에 이미지 인식(Image recognition) 분야에서 인간과 동등한 능력을 보였다. 이어서 2015년에는 음성 인식(speech recognition), 그리고 2017년에는 챗GPT의 기반인 ‘트랜스포머(Transformer)’ 모델이 개발되면서 독해력(reading comprehension)에서도 인간의 능력을 넘어서기 시작했다.
표현 학습이 높은 딥러닝 구조 찾기 – 인간에게 남겨진 과제
데이터 표현을 학습하는 딥러닝 모델은 주어진 작업마다 그 구성을 다르게 한다. 이는 데이터 유형에 따라 표현 학습 능력이 높은 딥러닝 구조가 다르기 때문이다. 이미지 분야에는 컨볼루셔널 신경망(CNN – Convolutional Neural Network), 언어 분야에서는 어텐션(Attention) 기반의 BERT와 GPT 등이 성능이 높은 것으로 알려져 있다.
최근 자동화된 딥러닝 모델 탐색을 위한 시도가 이루어지고 있다. ‘NAS(Neural Architecture Search : 신경망 구조 탐색)’는 주어진 데이터에 대해, 대표적인 신경망의 구성 요소를 조합해 테스트함으로써 가장 효과적인 딥러닝 모델을 찾기 위한 기술이다.
필자 강승우 위데이터랩 인공지능연구소장 겸 부사장은 펜타 컴퓨터를 거쳐 BEA, Oracle에서 최고 기술 아키텍트로서 기업의 IT 시스템 문제가 있는 곳의 해결사의 역할을 했다. 글로벌에 통하는 한국 소프트웨어 개발에 대한 열정으로 S전자 AWS 이벤트 로그 분석을 통한 이상징후 탐지, R사의 건축물 균열 탐지 등의 머신러닝 프로젝트를 진행했다. 현재는 딥러닝을 이용한 소프트웨어 취약점 탐지 자동화 연구와 머신러닝과 딥러닝강의를 진행하고 있으며, 비즈니스화에도 노력을 기울이고 있다. 최근 저서로 '머신러닝 배웠으니 활용해볼까요?'가 있다.
(*이 칼럼은 GTT KOREA의 편집 방향과 다를 수 있습니다.)
관련기사
- [강승우의 머신러닝 이야기] 인공지능이 꾸는 꿈, ‘AI의 환각’
- [강승우의 머신러닝 이야기] 인공지능에게 지식을 배우는 법 가르치는 ‘퓨 삿 러닝’
- [강승우의 머신러닝 이야기] 인공지능 시대 위협하는 ‘적대적 공격’
- [강승우의 머신러닝 이야기] 의미를 담은 숫자 만들기 - 임베딩(Embedding)
- [강승우의 머신러닝 이야기] 인공지능을 위한 집단 지성 – 분산 학습
- [강승우의 머신러닝 이야기] 어떻게 데이터가 변하니 – 데이터 드리프트(Data Drift)
- [강승우의 머신러닝 이야기] 챗GPT는 어떻게 교육받을까?
- [강승우의 머신러닝 이야기] 무료 데이터에 대한 독점적 권리는 누구에게 있는가
- [강승우의 머신러닝 이야기] AI의 편견을 만드는 데이터 편향
- [강승우의 머신러닝 이야기] 진짜보다 진짜같은 가짜 ‘딥페이크’
- 서비스형 머신러닝 MLaaS 시장, 연평균 36.2% 폭풍 성장
- 챗GPT를 활용한 기업의 디지털 전환 전략
- 인간은 AI 생성 콘텐츠를 얼마나 감지할까?
- 소프트웨어 개발자 역량 강화하는 생성AI ‘AIDA’
- 쓰임 많은 뇌컴퓨터 인터페이스, AI 날개 달고 급성장
- ARM 8코어 기반 고성능 AI NAS
- 소프트웨어 테스트 서비스 시장, 매년 10.77% 성장
- 음성서비스 확대로 '음성 텍스트 변환 API' 시장 동반 성장