
작년 말에 공개된 챗GPT가 사람들의 상상력을 자극하고 있다. 세일즈포스는 협업 도구 슬랙(Slack)에 챗GPT를 도입하여 문서 요약, 초안 작성 등의 기능을 제공할 것이라 밝혔다.
쇼피파이(Shopify)는 개인화된 추천으로 고객의 쇼핑을 도와주는 쇼핑 어시스턴스(Shopping Assistance)에 챗GPT를 도입했다. 이외에도 챗GPT를 기반으로 하는 다양한 서비스가 구상되고 있다.
마이크로소프트 창업자 빌 게이츠는 지난 달 언론과의 인터뷰에서 “인터넷 발명만큼 중대한 발명이 될 수 있다”라며 챗GPT에 대해 세상을 바꿀 기술이라 평가했다.
이처럼 놀라운 기능을 보여주는 챗GPT는 학습에 많은 시간과 자원이 사용된다. 1750억개의 매개변수를 적절한 값으로 훈련시키는 데에는 5000만 달러(약 650억)의 비용과 1만개의 GPU가 사용되었다. 그리고, 하루 운영 비용은 10만 달러(약 1억 3천만원)에 이른다.
이처럼 거대한 인공지능 언어 모델(LLM : Large Language Model)의 훈련은 분산 학습(Distributed Learning) 기술에 기반한다.
최근 인기를 끌고 있는 생성형 인공지능은 수천억개 이상의 매개변수를 가지고 있다. 이처럼 많은 매개변수 계산은 하나의 서버로 처리할 수는 없다.
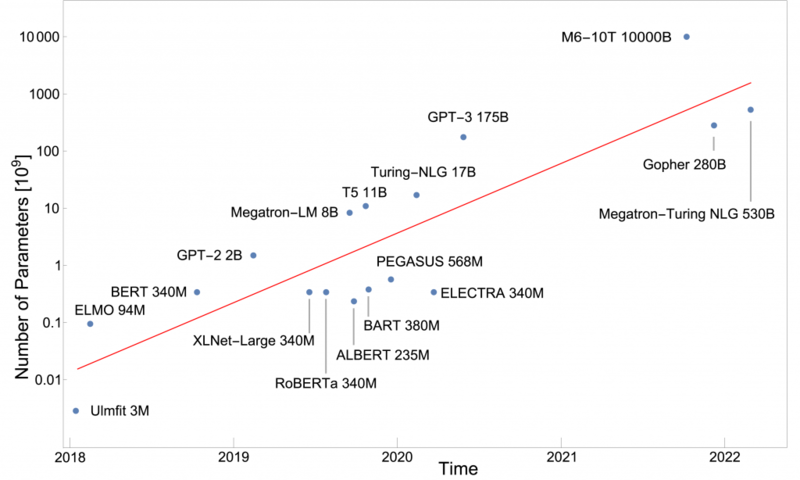
예를 들어 챗GPT는 1750억 개의 매개변수를 다량의 책과 위키피디아, 그리고 웹 상의 문서에서 수집된 5000억 개의 단어로 훈련시켰다. 이를 한 개의 GPU로 훈련시키려면 약 355년이 걸린다(참고 : OpenAI's GPT-3 Language Model: A Technical Overview (lambdalabs.com)). 또한 1750억 개의 매개변수는 약 700 기가 바이트의 메모리를 필요로 한다. 이는 수십 기가에 불과한 현재 GPU의 메모리로는 처리할 수가 없다.
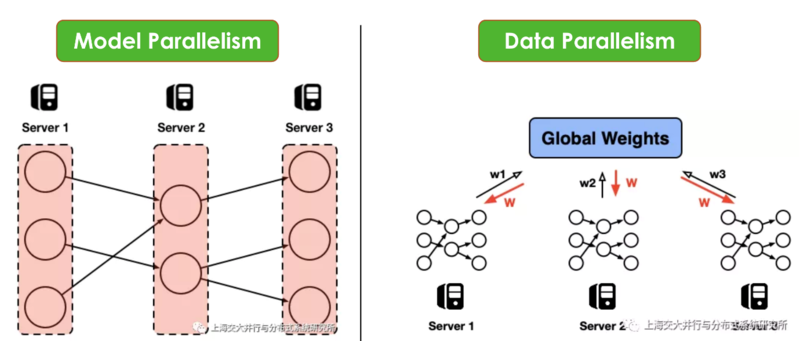
이와 같은 문제를 해결하기 위한 사용되는 기술이 분산 학습(Distributed Learning)이다. 분산 학습은 작업을 분산하는 방법에 따라 모델 병렬화(Model Parallelism)와 데이터 병렬화(Data Parallelism) 두 가지로 나눌 수 있다.
모델 병렬화는 하나의 모델이 여러 서버(혹은 GPU)상에 올려놓고 훈련하는 방식이다. 하나의 GPU의 메모리가 모델 파라미터를 담기에 부족할 경우에 사용할 수 있다.
데이터 병렬화는 동일한 모델을 다수의 서버에서 서로 다른 데이터로 훈련시킨다. 이를 통해 모델 훈련 시간을 단축할 수 있다.
분산 훈련은 다수의 서버가 하나의 모델 훈련에 참여하기 때문에 서버 간의 조율을 위한 통신이 매우 중요하다. 챗GPT는 마이크로소프트 애저(Azure) 클라우드 상에서 고대역폭(High Bandwidth) 네트워크으로 연결된 1만 개의 GPU로 분산 훈련되었다.
분산 훈련에는 GPU와 네트워크 같은 하드웨어 뿐 아니라, 훈련 결과를 취합하고 다수의 서버 상의 매개 변수를 동기화하는 소프트웨어 기술이 필요하다. 파이토치(PyTorch)와 텐서플로우(Tensorflow)는 이를 위한 소프트웨어 패키지를 제공하고 있다. 그리고 레이(Ray) 와 같은 분산 훈련을 위해 전문화된 오픈소스 기반의 별도 패키지도 있다.
참고로 챗GPT는 분산 훈련을 위해서 Ray를 사용하고 있다(참고 : How Ray, a Distributed AI Framework, Helps Power ChatGPT - The New Stack ).
날로 높아지는 챗GPT의 인기로 그 사용량이 급격히 증가하고 있다. 이러한 사용량의 증가로 향후 챗GPT를 안정적으로 운영하기 위해서는 3만 개 이상의 GPU가 필요할 것으로 예상하고 있다(참고 : ChatGPT Will Command More Than 30,000 Nvidia GPUs: Report | Tom's Hardware). 이에 따라 대량의 장비를 효율적으로 관리할 수 있는 인공지능을 위한 집단 지성인 분산 학습, 분산 운영 기술의 중요성이 높아지고 있다.
필자 강승우 위데이터랩 인공지능연구소장 겸 부사장은 펜타 컴퓨터를 거쳐 BEA, Oracle에서 최고 기술 아키텍트로서 기업의 IT 시스템 문제가 있는 곳의 해결사의 역할을 했다. 글로벌에 통하는 한국 소프트웨어 개발에 대한 열정으로 S전자 AWS 이벤트 로그 분석을 통한 이상징후 탐지, R사의 건축물 균열 탐지 등의 머신러닝 프로젝트를 진행했다. 현재는 딥러닝을 이용한 소프트웨어 취약점 탐지 자동화 연구와 머신러닝과 딥러닝강의를 진행하고 있으며, 비즈니스화에도 노력을 기울이고 있다. 최근 저서로 '머신러닝 배웠으니 활용해볼까요?'가 있다.
(*이 칼럼은 GTT KOREA의 편집 방향과 다를 수 있습니다.)
관련기사
- [강승우의 머신러닝 이야기] 어떻게 데이터가 변하니 – 데이터 드리프트(Data Drift)
- [강승우의 머신러닝 이야기] 챗GPT는 어떻게 교육받을까?
- [강승우의 머신러닝 이야기] 무료 데이터에 대한 독점적 권리는 누구에게 있는가
- [강승우의 머신러닝 이야기] AI의 편견을 만드는 데이터 편향
- [강승우의 머신러닝 이야기] 진짜보다 진짜같은 가짜 ‘딥페이크’
- [강승우의 머신러닝 이야기] 되돌아 보는 인공지능의 역사
- [강승우의 머신러닝 이야기] 전이학습, 머신 간의 지식 전수
- [강승우의 머신러닝 이야기] 머신러닝이 배우는 것
- [강승우의 머신러닝 이야기] 설명 가능한 AI를 위한 기술
- [강승우의 머신러닝 이야기] 설명 가능한 AI
- [강승우의 머신러닝 이야기] 딥러닝 모델을 노리는 적대적 공격
- [강승우의 머신러닝 이야기] 딥러닝에서 활용도 높은 잠재공간을 누비자
- 클라우드와 결합된 챗GPT 제공하는 '마이크로소프트 애저 오픈AI 서비스'
- 신기술로 급성장하는 엔터프라이즈 AI, 2027년 582억 5000만 달러 전망
- “생성형 AI, 돌풍은 맞지만 기존 AI 기술과 마찬가지로 근본적인 문제 해결 못해”
- 챗GPT 연계 AI 보안 서비스가 뜬다
- 변호사도 인정한 GPT-4 적용된 AI 법률 비서
- 세계 최대 온라인 갤러리가 크롤러의 AI 머신러닝 수행을 금지한 이유
- 마이크로소프트'ISV 성공 프로그램' 국내 SW 기업 성장 지원
- AI와 생산성 도구 결합해 작업 방식 바꾸고 생산성 향상
- 생성 AI가 STEM 교육에 미치는 영향
- GPT-4 기반 AI, 소비자 불만 민원 편지도 잘 쓰네!
- [강승우의 머신러닝 이야기] 의미를 담은 숫자 만들기 - 임베딩(Embedding)
- 솔트룩스, 챗GPT '루시아'기반 인지검색 서비스 발표
- [강승우의 머신러닝 이야기] 인공지능 시대 위협하는 ‘적대적 공격’
- 위데이터랩, 서울바이오허브 AI 특화교육 참여
- [강승우의 머신러닝 이야기] 인공지능에게 지식을 배우는 법 가르치는 ‘퓨 삿 러닝’
- ‘슬랙 GPT’, 생성AI 서비스로 기업 생산성↑
- [강승우의 머신러닝 이야기] 인공지능이 꾸는 꿈, ‘AI의 환각’
- [강승우의 머신러닝 이야기] 딥러닝의 표현 학습
- [신간안내]GPT 활용 백서, “챗GPT 업무 활용 마스터”