LLM이 에이전트 역할을 수행하기 위해서는 도메인 별 지식과 문제 해결을 위한 툴 선택 및 활용 능력, 대화의 맥락 이해, 수집된 정보 활용 등 다양한 능력이 필요하다.
LLM 올인원 솔루션 기업 올거나이즈(대표 이창수)가 LLM의 에이전트 역량을 평가하는 ‘올인원 벤치마크(All-in-One Benchmark)’를 공개한다고 3일 밝혔다.
올인원 벤치마크는 LLM의 에이전트 성능을 종합 평가하는 플랫폼으로, LLM 모델 별로 비교 분석할 수 있다. 올거나이즈의 자체 소형언어모델(sLLM)과 ‘챗지피티(ChatGPT)’, ‘엑사원(EXAONE)’, ‘큐원(Qwen)’, ‘딥시크(DeepSeek)’ 등 12개의 LLM을 평가할 수 있으며, 결과는 대시보드 형태로 제공된다.
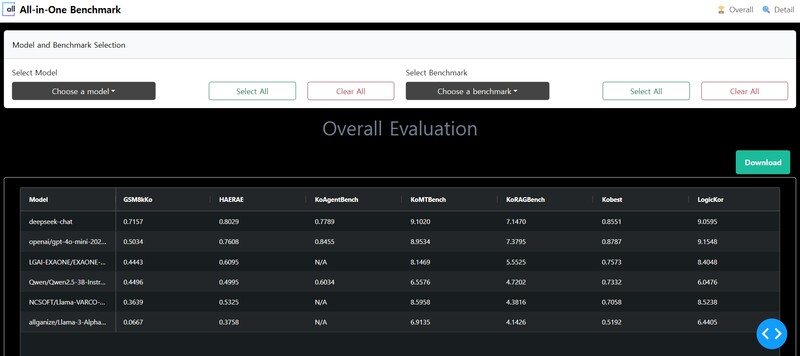
특히 에이전트 역할뿐 아니라 일반적인 언어 이해, 지식수준, 명령 준수 등 LLM의 성능을 종합적으로 평가할 수 있다. 이를 통해 기업은 가장 적합한 LLM을 선택할 수 있다.
에이전트 종합적 성능 평가는 ▲ 스스로 외부 도구를 호출하는 ‘툴 콜링(tool calling)’ 능력 평가는 ‘BFCL’ ▲한국어 환경에서의 툴 콜링 능력 평가는 ‘펑션챗벤치(FunctionChatBench)’ ▲ 유통, 항공 등 실제 산업 현장에서 LLM의 문제 해결 능력을 평가하는 ‘타우벤치(TauBench)’ 등 3가지가 활용된다.
새로운 LLM의 성능도 확인할 수 있다. 새로 나온 LLM 이름을 입력하면 플랫폼이 모델의 API를 자동으로 구현해 평가한다. 이를 통해 LLM이 새로 개발될 때마다 각 벤치마크의 개별 코드를 실행해 동일 작업을 수차례 진행하는 기존 업무의 비효율성을 해결할 수 있다.
특히 대규모 데이터셋과 복잡한 벤치마크에서도 평가할 수 있어 평가 시간을 단축할 수 있다. 동일 모델 평가 결과, 기존 벤치마크의 경우 약 1시간 30분, 올거나이즈의 플랫폼은 약 20분이 소요됐다.
올거나이즈는 기업의 AI 모델 도입에 도움이 될 수 있는 LLM 평가 플랫폼을 지속적으로 고도화할 예정이다.
올거나이즈 이창수 대표는 “에이전트 역할을 정확히 수행하는 LLM 개발을 위해, 기존 LLM의 에이전트 성능을 평가하고 향상하는 학습 방법을 연구하고 있다.”라고 말했다.
관련기사
- 올거나이즈, ‘코오롱베니트 AI 얼라이언스’ 합류...AI 기술·LLM 앱 공급망 확대
- 올거나이즈, 이원강 부대표 영입...도쿄거래소 상장 목표
- 한국어 실무에 특화된 LLM
- 국내에도 '검색증강생성 RAG' 전문 리더보드 등장
- 올거나이즈, LLM 서비스에 다중 인증으로 보안 강화
- 올거나이즈, 금융 LLM 리더보드·데이터세트 공개
- 딥엘, 차세대 LLM·쓰기 기능 강화된 API 솔루션 출시…언어장벽 극복·시장 경쟁력 강화
- ‘링크브릭스 호라이즌AI’ 법인 설립으로 sLLM 플랫폼 개발 박차
- 컴트루테크놀로지, 생성AI·LLM 데이터 보안 솔루션 ‘스핑크스 AI’ 출시
- [2025년 전망] AI·자동화 핵심 ‘에이전트 AI·내장형 AI·LLM 기반 데이터 관리’
- 노트북에서 쌩쌩 돌아가는 오픈소스 LLM '팔콘 3'
- LLM·사기 방지 기능 결합한 ‘AI 신원 확인’ 솔루션...정확도↑
- 비전문가도 빠르고 정확하게 "데이터 검색 및 분석"
- 엔비디아, NIM에서 딥시크-R1 지원
- 애브포인트, ‘마이크로소프트365 코파일럿 모니터링 솔루션’ 기능 고도화
- 올거나이즈, 도쿄메트로에 국산 AI 기술 공급
- ‘AI 에이전트 구축 자동화 API 플랫폼’...사전 학습된 AI 모델로 개발 효율↑
- 데이터 자동 검증하는 오픈소스 ‘LLM 평가 솔루션’...‘RAG 기반 환각 감지·쌍별 선호도 판단·개인정보 보호 지원’
- LG CNS, 금융 산업 특화 LLM 평가 도구 출시
- “3명 중 1명, 인간 전문가보다 챗GPT 신뢰”...법률·의료 분야는 신중
- ‘RAG 평가 오픈소스 프레임워크’...AI 에이전트 정확성·신뢰성·설명가능성 보장
- 올거나이즈, 보안 강화된 MCP 기반 '알리 에이전트 빌더' 출시
- 일본 시장 1위 기록한 국산 LLM 기반 노코드 서비스 ‘알리’